Schema Introspection – JSON based metadata of the schemas or excel file containing the table vs column details vs constraints vs keys. Extract metadata (tables, columns, types, constraints) from both source and target using introspection tools.
Semantic Embedding – Apply NLP preprocessing (tokenization, lemmatization, synonym expansion) to standardize naming.Use transformer models (e.g., BERT, SentenceTransformers) with positional encoding to embed column metadata. Though positional encoding is challenging – consider using sentence transformers or schema2vec-like models to embed column metadata (name + type + sample values).
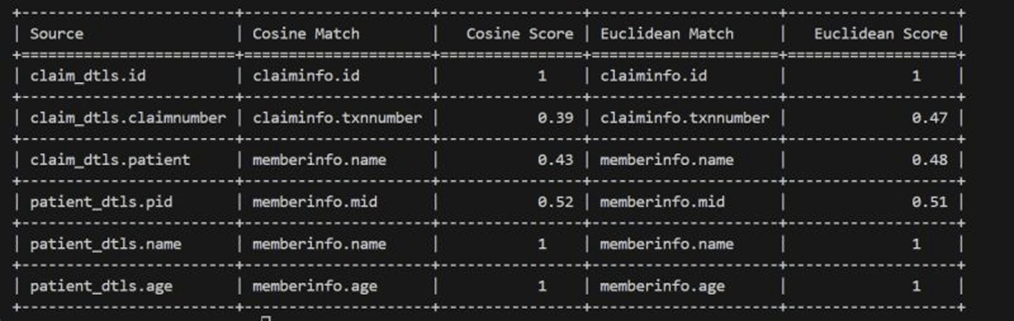
Similarity Scoring – Compute semantic similarity using cosine or Euclidean distance to identify best-fit column mappings. Need to explore Jaccard similarity or Levenshtein distance as a fallback.
Script & Casting – Handle data type mismatches using a compatibility matrix and safe casting rules.Flag low-confidence mappings for manual review, enabling human-in-the-loop validation.
The agent is modular, extensible, and can be integrated into existing data platforms or exposed via APIs/UI for business users.
Would love to hear how others are approaching schema intelligence and semantic mapping in real-world migrations.
Below for basic metadata using non domain models – if we use domain specific models as per the use case the scoring would be significant and it would be easy for the migration..